The concept of a graph in mathematics is simply a collection of elements which are typically called Nodes and are joined together by Edges. Each Node represents a piece of information in the graph and each Edge represents some relationship or connection between any of the two Nodes (Cox, 2017).
A graph database is simply a database that models itself on the connections that Nodes represent in a mathematical graph structure.
It helps to show connections between pieces of information in a much more natural flow than other database types.
Graph databases are often schema-less in order to provide a high level of flexibility.
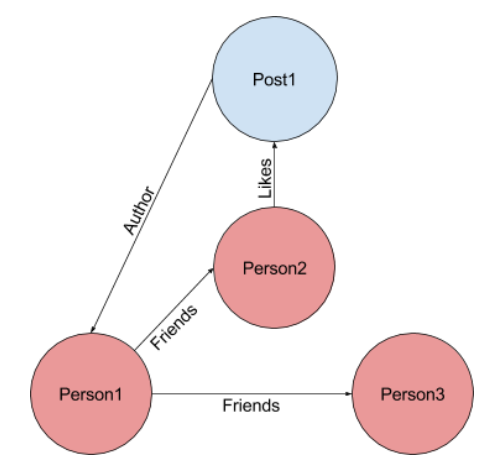
Entities can be modelled as Nodes and Relationships thereof as Edges, for example:
There are many use cases and application domains for graph databases such as:
- Fraud Detection (Neo4j, 2018)
Real-time analysis of data can connect fraudsters and sophisticated scams before they are carried out. - Real-time Recommendations
Personalise products by knowing the connections between customers and products as and when they happen. - Social Networking and Social Marketing
Link people and places as events happen to provide a more seamless social experience; this is often used to target individuals from marketing perspectives as well. - Identify and Access Management
Track individuals, groups and assets during authorisation for specified access where necessary within an organisation or country. - Network and IT operations (Carey, 2017)
Visualising interconnected networked devices and systems and their individual relationships.
In spite of their name, relational (SQL) databases are not appropriate for the present exceedingly associated information, since they don’t heartily store connections between information components.
Relational databases actually take their name from the highly specific mathematical notion of a ?relation? (table) ? as part of E.F. Codd?s relational algebra. The name does not derive from describing relationships between data (Hunger, Boyd, Lyon, 2016).
Relational databases get slower over time due to the amount of growing queries about data relationships. These types of databases are not built to handle connected data at scale and require a large amount of JOINs between database tables to come close to the relationships that are needed to provide a suitable analysis.
By doing this, overall database performance and query time start to degrade.
Graph databases, like NoSQL structures, come in a varying array of specifications and approaches.
They turn traditional database theorem inside out in that both Relational and NoSQL databases store data as attributes and join them by means of relations or connections such as primary or foreign keys.
These are in turn constrained to multiple sections of data.
However, Graph databases use the connections between pieces of data as the actual relationships themselves and these represent the commonalities between entities and individual pieces of data.
They have an index data structure where it is never required to touch anything unrelated to a given query and a real-time update on big data simultaneously.
While all the different databases have their place, graph databases exceed at interconnected information and relationships therein.
**
References:**
Cox, G. (2017) Introduction to Graph Databases [Online] Compose.com, Available from: https://www.compose.com/articles/introduction-to-graph-databases/
Neo4j (2018) Graph Database Use Cases [Online] Neo4j.com, Available from: https://neo4j.com/use-cases/
Carey, S. (2017) Seven enterprises using graph databases: Popular graph database use cases, from recommendation engines to fraud detection and search [Online] ComputerWorldUK.com, Available from: https://www.computerworlduk.com/galleries/data/7-most-popular-graph-database-use-cases-3658900/
Hunger, M., Boyd, R., Lyon, W. (2016) RDBMS & Graphs: Why Relational Databases Aren?t Always Enough [Online] Neo4j.com, Available from: https://neo4j.com/blog/rdbms-graphs-why-relational-databases-arent-enough/
Neubauer, P. (2010) Graph Databases, NOSQL and Neo4j [Online] InfoQ.com, Available from: https://www.infoq.com/articles/graph-nosql-neo4j
